
안녕하세요 Steve-Lee입니다. Lecture 8 Part 1. Deep Learning을 위한 CPU와 GPU 지금 바로 시작합니다!
모두를 위한 cs231n
모두를 위한 cs231n 😀
👉🏻 시작합니다! 🎈
모두를 위한 cs231n (feat. 모두의 딥러닝 & cs231n)
👉🏻 Neural Network 기초 📗
* Backpropagation
Lecture4. Backpropagation and Neural Network. 오차역전파에 대해서 알아보자😃
👉🏻 Training Neural Network Part I 📑
- Activation Function 파헤치기
Lecture 6. Activation Functions에 대해 알아보자
Lecture 6. Activation Functions - ReLU함수의 모든 것
- Data Preprocessing
Lecture 6. Training Neural Network - Data Preprocessing
- Weight Initialization
Lecture 6. Weight Initialization
- Batch Normalization
Lecture 6. Batch Normalization
👉🏻 Deep Learning CPU와 GPU ⚙️
Lecture 8 - Part1. Deep Learning 을 위한 CPU와 GPU
👉🏻 Deep Learning Framework ☕️
Lecture 8 - Part2. Deep Learning Framework
👉🏻 TensorFlow Fraemwork 🧱
Lecture 8 - Part3. TensorFlow Framework
👉🏻 PyTorch Framework 🔥
Lecture 8 - Part3. PyTorch Framework
👉🏻 Generative Model
모두를 위한 cs231n (feat. 모두의 딥러닝 & cs231n)
cs231n 시작합니다! 안녕하세요. Steve-Lee입니다. 작년 2학기 빅데이터 연합동아리 활동을 하면서 동기, 후배들과 함께 공부했었던 cs231n을 다시 시작하려고 합니다. 제가 공부하면서 느꼈던 점들과
deepinsight.tistory.com
Part1. Deep Learning 을 위한 CPU와 GPU
Part1. 에서는 다음의 내용들을 학습합니다.
- CPU와 GPU에 대해 알아보자
- CPU와 GPU 비교
- GPU 프로그래밍
- GPU 학습시 발생하는 문제점 및 해결 방안
CPU, GPU에 대해 알아보자
CPU와 GPU의 차이는 뭘까?
딥러닝을 한 번쯤 구현해 보셨더라면 한 번쯤 생각해보셨을 만한 주제라고 생각합니다. 지금까지 왜 딥러닝에서 GPU가 CPU보다 좋은지에 대해 명확하게 언급하지 않고 넘어갔습니다. 오늘 제대로 짚고 넘어가 보도록 하겠습니다.😃
GPU란 무엇일까?

GPU는 graphics card 또는 Graphics Processing Unit이라고합니다.
사실 GPU는 computer graphics를 렌더링하기 위해 만들어졌습니다. 쉽게 말해 게임 등을 위해 만들어진 하드웨어입니다.
GPU의 양대 산맥으로는 NVIDIA와 AMD가 있지만 Deep Learning에서는 한 쪽만 선택합니다. 바로 NVIDIA입니다. 만약 AMD 그래픽 카드를 가지고 있다면 딥러닝을 사용하는데 문제가 많을 것입니다.
NVIDIA에 대해 살펴보면 NVIDIA는 수년간 딥러닝에 많은 공을 기울였다고 합니다. NVIDIA의 많은 엔지니어들은 딥러닝에 적합한 하드웨어를 만들기 위해 많은 노력을 기울인 것 같습니다. 그 결과 2017년 기준 Deep Learning 분야에서 NVIDIA가 독점적인 위치를 가지고 있습니다.

2020년 2월 기준으로도역시 NVIDIA Graphic Card가 독점적인 위치를 차지하고 있습니다.
CPU와 GPU를 본격적으로 비교하기 앞서 영상 한 편을 보고 오겠습니다.
영상 시청이 끝나면 보다 흥미가 생기지 않을까 생각합니다.
CPU와 GPU 비교하기
그러면 CPU와 GPU의 차이는 무엇일까요??
CPU와 GPU의 차이를 다음의 세가지 기준을 통해 비교해보도록 하겠습니다.
-
core의 수와 명령어를 처리하는 방식의 차이
-
메모리 사용 방식의 차이
-
Matrix Multiplication
우선 강의 자료를 바탕으로 알아보도록 하겠습니다.
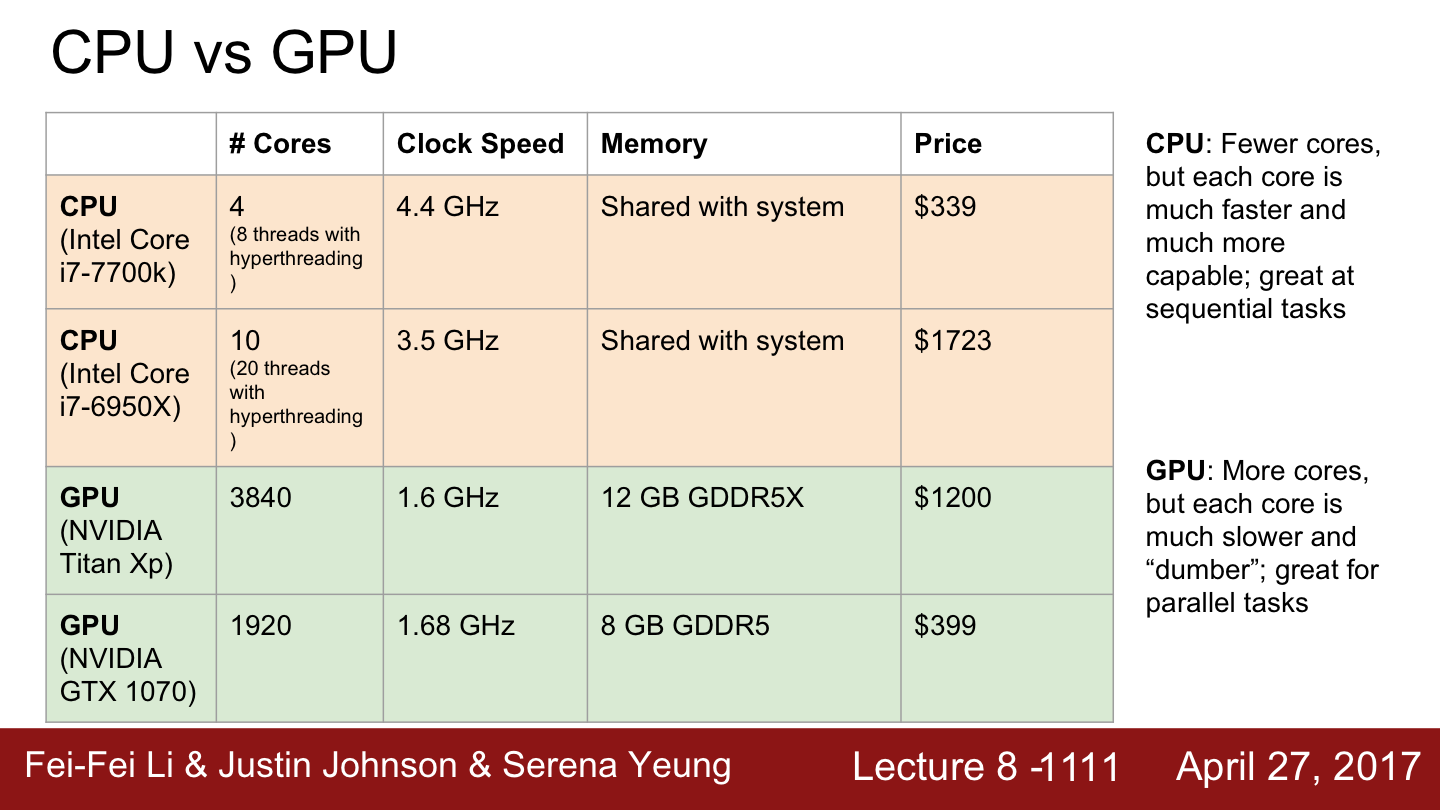
위의 두 개(주황색)는 Intel 최신(2017년 기준) 상업용 CPU들이고 밑에 두 개(녹색)는 NVIDIA의 최신 상업용 GPU들입니다. 여기에는 몇 가지 주요 트렌드가 있다고 합니다. CPU와 GPU 모두 임의의 명령어를 수행할 수 있는 범용 컴퓨팅 머신입니다.
core수와 명령을 수행하는 방식의 차이
CPU의 경우 core의 수가 적습니다.
GPU의 경우 수 천개의 core가 있습니다.
단순히 코어의 수만 놓고 보면 CPU에 비해 GPU의 코어수가 압도적으로 많습니다. 하지만 CPU와 GPU 코어는 1:1로 비교할 수 없습니다.
GPU 코어들은 독립적으로 동작하지 않습니다. 코어마다 독립적인 테스크가 있는 것이 아니라 많은 코어들이 하나의 테스크를 병렬적으로 수행하는 것입니다. 하지만 GPU의 코어 수가 많다는 것은 어떤 테스크가 주어졌을 때 일을 병렬로 수행하기 아주 적합하다는 것을 의미합니다.
반면 CPU의 경우 GPU에 비해 core의 수는 적지만 많은 일들을 독립적으로 수행할 수 있습니다.
오늘날의 상업용 데스크탑 CPU의 경우 코어가 4개에서 6개이며 많으면 10개 정도입니다. 그리고 hyperthreading 기술과 불어 CPU는 8~12개의 스레드를 동시에 실행시킬 수 있습니다. 예를들어 위의 그래프에서 i7-6950X의 경우 hyperthreading으로 한 번에 20가지 일을 할 수 있는 것입니다. 모든 CPU 명령어들은 정말로 많은 일을 독립적으로 수행 할 수 있습니다.
메모리 사용 방식의 차이
CPU는 대부분의 메모리를 RAM에서 끌어다 씁니다. 반면 GPU는 RAM이 내장되어 있습니다. GPU는 core 사이의 캐싱을 하기 위한 다계층 캐싱 시스템을 가지고 있습니다.
또 한가지 말씀드릴 점은 메모리에 관한 것입니다. CPU에도 캐시가 있습니다. 하지만 비교적 작습니다. 그렇기에 CPU는 대부분의 메모리를 RAM에서 끌어다 씁니다. RAM은 일반적으로 8, 12, 16, 32 GB 정도입니다. 반면 GPU는 칩 안에 RAM이 내장되어 있습니다. 실제 RAM과 GPU 간의통신은 상당한 보틀넥을 초래합니다.그렇기 때문에 GPU는 보통 칩에 RAM이 내장되어 있습니다. Titan XP의 경우 내장 메모리가 12GB 정도됩니다. Titan XP는 12GB 메모리와 GPU 코어 사이의 캐싱을 하기 위한 일종의 다계층 캐싱 시스템을 가지고 있습니다. 이는 CPU 캐싱 계층구조와 아주 유사합니다.
CPU는 메모리를 RAM으로부터 끌어다 쓰고 GPU는 내장 메모리를 사용한다고 기억해두시면 좋을것 같네요!
Matrix Multiplication
CPU는 범용처리에 적합합니다. CPU는 아주 다양한 일을 할 수 있습니다. GPU는 병렬 처리에 더 특화되어 있습니다. GPU에서 정말 잘 동작하고 아주 적합한 알고리즘은 바로 행렬곱 연산(Matrix multiplication) 연산입니다. 연산입니다.

오른쪽 행렬(A x C)은 왼쪽 두 행렬의 내적입니다. 그리고 이 때 내적 연산은 모두 독립입니다. 오른쪽 행렬을 살펴보면 각각의 원소가 전부 독립적입니다. 따라서 모두 병렬로 수행될 수 있습니다.
그리고 각 원소들은 모두 같은 일을 수행합니다. 두 개의 벡터를 내적하는 것입니다. 다만 각각의 입력 데이터만 조금씩 다를 뿐입니다. GPU는 결과 행렬의 각 요소들을 병렬로 계산할 수 있으며 이러한 특성 때문에 GPU는 엄청나게 빠르게 연산이 가능합니다. 이런 연산은 GPU가 정말 잘하는 것들입니다. CPU였다면 각 원소를 하나씩만 계산할 것입니다.
물론 CPU라고 단순하게 동작하는 것은 아닙니다. CPU도 여러 개의 core가 있고 Vectorized Instruction들이 존재합니다. 그렇다고 해도 아주 massive 한병렬화 문제에 관해서는 GPU의 처리량이 압도적으로 좋습니다.
정리
NVIDA Blog에 각각의 특징이 잘 정리되어 인용해왔습니다.
CPUGPU
|
CPU |
GPU |
|
Central Processing Unit |
Graphics Processing Unit |
|
Several cores |
Many cores |
|
Low latency |
High throughput |
|
Good for serial processing |
Good for parallel processing |
|
Can do a handful of operations at once |
Can do thousands of operations at once |
-
CPU - 적은 core수, 낮은 대기시간, 순차적 프로세싱에 이점, 한 번에 소수의 작업 수행
-
GPU - 많은 core수, 높은 처리량, 병렬 프로세싱에 이점, 한 번에 수천개의 계산 수행
✅ Lecture 15를 공부하면서 든 생각(질문)
📌 CPU의 Low latency와 GPU의 High throughput이 정확히 무엇일까?(이부분에 대한 공부와 포스팅 필) - 20.06.08.mon-
GPU Programming
다음으로 GPU의 programming 방법에 대해 알아보도록 하겠습니다.
NVIDIA CUDA

NVIDIA에서 CUDA를 지원하는데 그 코드를 보면 c언어 스럽게 생겼습니다. 하지만 GPU에서 실행되는 코드입니다. CUDA코드를 작성하는 것은 상당히 까다로운 작업이라고 합니다 GPU의 성능을 전부 짜낼 수 있는 코드를 작성하기란 상당히 힘든 작업입니다. 아주 세심하게 메모리 구조를 관리해야 합니다. 가령 cache misses나 branch mispredictions같은 것들을 전부 고려해야 합니다.
정리하면 우리가 스스로 아주 효율적인 CUDA code를 작성하는 것은 상당히 어렵습니다. 때문에 NVIDIA는 GPU에 고도로 최적화 시킨 기본연산 라이브러리를 배포해 왔습니다.

cuBLAS는 다양한 행렬곱을 비롯한 연산들을 제공합니다. 이는 아주 고도로 최적화되어 있습니다. 이는 GPU에서 아주 잘 동작하고 하드웨어 사용의 이론적 최대치까지 끌어올려 놓은 라이브러리입니다. 유사하게 cuDNN이라는 라이브러리도 있습니다.이는 convolution, forward/backward pass, batch norm, rnn 등 딥러닝에 필요한 거의 모든 기본적인 연산들을 제공하고 있습니다. 따라서 실제로는 딥러닝을 위해 CUDA 코드를 직접 작성하는 일은 없을 것입니다. 이미 다른 사람들이 작성한 코드를 불러와서 쓰기만 하면 됩니다.
CUDA 과 유사한 언어가 있는데 OpenCL입니다. OpenCL의 경우 NVIDIA GPU에서만 동작하는 것이 아니라 AMD 그리고 CPU에서도 동작합니다. 하지만 OpenCL은 아직 딥러닝에 극도로 최적화된 연산이나 라이브러리가 개발되지는 않았습니다(2017 기준) 그래서 CUDA보다는 성능이 떨어진다고 합니다.
한편 GPU 프로그래밍을 직접 해보면 익힐 수 있는 다양한 리소스들이 있다고 합니다. 아주 massisve한 병렬처리 아키텍쳐를 다루는 것이기 떄문에 코드를 작성하는 패러다임도 조금은 다르다고 합니다. 하지만 이 이상의 영역은 강의 주제에서 벗어나기 떄문에 여기까지만 알면 될 것 같습니다.
Benchmark
-
CPU와 GPU의 성능 벤치마크 비교
-
CUDA와 cuDNN의 성능 벤치마크 비교

실제 CPU와 GPU의 성능을 벤치마크한 표를 통해 GPU가속의 효과를 보실 수 있습니다.

또 하나의 벤치마크로는 convolution연산에 cuDNN을 사용한 것과 일반적인 CUDA를 사용한 것입니다.
동일한 하드웨어와 동일한 딥러닝 프레임워크를 사용하고 다른점은 오직 cuDNN과 CUDA입니다. CUDA는 조금 최적화가 덜 된것이었습니다. 평균적으로 cuDNN이 3배정도의 속도향상이 있습니다.
CPU / GPU Communication
드디어 마지막 세션입니다. 조금만 더 힘내주세요!😄
그렇다면 병렬 처리를 빠르게 할 수 있는 GPU로 학습을 할 경우 어떤 문제가 발생할 수 있을까요?

실제로 GPU로 학습할 때 생기는 문제 중 하나는 바로 Model과 Model의 가중치는 전부 GPU RAM에 상주하고 있는 반면에 실제 Train data(Big data가 될 수 있습니다)는 SSD와 같은 하드드라이브에 상주하고 있다는 것입니다. 때문에 Train time에 디스크에서 데이터를 읽어드리는 작업을 세심하게 신경쓰지 않으면 보틀넥(Bottleneck)이 발생할 수 있습니다.

GPU는 forward/backward가 아주 빠른 것이 사실이지만 디스크에서 데이터를 읽어드리는 것이 보틀넥이 되는 것입니다. 이는 상당히 좋지 않은 상황이고 느려지게 됩니다.
이에 대한 해결책 중 하나는 데이터셋이 작은 경우에는 전체를 RAM에 올려 놓는 것입니다.
데이터 셋이 작지 않더라도 서버에 RAM 용량이 크다면 가능할 수도 있을 것입니다.
혹은 HDD 대신에 SSD를 사용하는 방법이 될 수도 있습니다.
데이터를 읽는 속도를 개선시킬 수 있는 것입니다. 또 다른 방법은 CPU의 다중 스레드를 이용해서 데이터를 RAM에 미리 올려 놓는 것(pre-fetching)입니다. 그리고 buffer에서 GPU로 데이터를 전송시키게 되면 성능 향상을 기대할 수 있습니다.
물론 이런 설정 자체가 조금 까다롭긴 하지만 GPU는 빠른데 데이터 전송 자체가 충분히 빠르지 못하면 보틀넥이 생길 수 밖에 없습니다.
정리
-
CPU와 GPU의 특징에 대해 알아보았습니다
- 코어 수와 명령을 처리하는 방식의 차이
- 메모리 활용 방식의 차이
- Matrix Multiplication
-
Deep Learning에서 병렬 연산을 위해 GPU가 필요한 이유에 대해서 배워보았습니다
- GPU Programming에 대해 배워보았습니다
- GPU에서 실행되는 코드를 알아봅니다
- 동일한 하드웨어와 동일한 프레임워크를 사용했을 때 연산 속도의 차이를 벤치마크 비교할 수 있습니다
- GPU학습시 발생할 수 있는 bottleneck 문제에 대해 알아보았습니다
긴 글 읽으시느라 고생 많으셨습니다. 이상 Steve-Lee였습니다!🤗
Next
Deep Learning Framework
[모두를 위한 cs231n] Lecture 8 - Part2. TensorFlow Framework 1부
안녕하세요 Steve-Lee입니다. Lecture 8 - Part 2은TensorFlow Framework입니다. 구글에서 개발한 Deep Learning 대표 Framework TensorFlow, 지금 시작합니다! 지난 시간에 우리는 Deep Learning을 위..
deepinsight.tistory.com
참고자료
-
cs231n Lecture8
-
[NVIDIA Blog] What’s the Difference Between a CPU and a GPU?
[Deep Learning] NVIDIA CUDA란 무엇인가?
안녕하세요 Steve-Lee입니다. cs231n을 공부하던 중 NVIDIA CUDA에 대한 질문이 나와 정리해보려고 합니다. NVIDIA Bog와 Google 검색을 참고하여 정리합니다. CUDA란 무엇인가? NVIDIA blog에 의하면 우리는 삶..
deepinsight.tistory.com
'Deep Learning > 모두를 위한 cs231n' 카테고리의 다른 글
| [모두를 위한 cs231n] Lecture 8 - Part2. Deep Learning Framework (0) | 2020.05.11 |
|---|---|
| [모두를 위한 cs231n] Lecture 8 - 개요 (0) | 2020.05.08 |
| [모두를 위한 cs231n] Lecture 8 - Part4. PyTorch Framework (0) | 2020.05.07 |
| [모두를 위한 cs231n] - Lecture4. Backpropagation and Neural Network. 오차역전파에 대해서 알아보자😃 (0) | 2020.04.30 |
| [모두를 위한 cs231n] Lecture 1. Introduction. 앞으로 이런 것들을 배울거에요😄 (0) | 2020.04.30 |




댓글