안녕하세요 Steve-Lee입니다. 지난 시간에 이어 Lecture 6. Training Neural Network에 대해 배워보도록 하겠습니다. 이번 시간에는 Data Preprocessing 방법에 대해 알아보도록 하겠습니다.
모두를 위한 cs231n
모두를 위한 cs231n 😀
👉🏻 시작합니다! 🎈
모두를 위한 cs231n (feat. 모두의 딥러닝 & cs231n)
👉🏻 Neural Network 기초 📗
* Backpropagation
Lecture4. Backpropagation and Neural Network. 오차역전파에 대해서 알아보자😃
👉🏻 Training Neural Network Part I 📑
- Activation Function 파헤치기
Lecture 6. Activation Functions에 대해 알아보자
Lecture 6. Activation Functions - ReLU함수의 모든 것
- Data Preprocessing
Lecture 6. Training Neural Network - Data Preprocessing
- Weight Initialization
Lecture 6. Weight Initialization
- Batch Normalization
Lecture 6. Batch Normalization
👉🏻 Deep Learning CPU와 GPU ⚙️
Lecture 8 - Part1. Deep Learning 을 위한 CPU와 GPU
👉🏻 Deep Learning Framework ☕️
Lecture 8 - Part2. Deep Learning Framework
👉🏻 TensorFlow Fraemwork 🧱
Lecture 8 - Part3. TensorFlow Framework
👉🏻 PyTorch Framework 🔥
Lecture 8 - Part3. PyTorch Framework
👉🏻 Generative Model
모두를 위한 cs231n (feat. 모두의 딥러닝 & cs231n)
cs231n 시작합니다! 안녕하세요. Steve-Lee입니다. 작년 2학기 빅데이터 연합동아리 활동을 하면서 동기, 후배들과 함께 공부했었던 cs231n을 다시 시작하려고 합니다. 제가 공부하면서 느꼈던 점들과
deepinsight.tistory.com
Training Neural Network Part I(Lecture 6)는 다음의 순서대로 진행됩니다. 참고해 주세요.
Part I Index
Activation Functions- Data Preprocessing
- Weight Initialization
- Batch Normalization
- Babysitting the Learning Process
- Hypperparameter Optimization
Data Preprocessing
지금부터는 데이터 전처리에 대해 배워보도록 하겠습니다.
일반적으로 입력 데이터는 전처리를 해줍니다. Machine Learning 수업에서 다뤄 보신 분들도 계실 것입니다.
가장 대표적인 전처리 과정은 'zero-mean'로 만들고 'normalize'하는 것입니다. normalize는 보통 표준편차로 합니다.
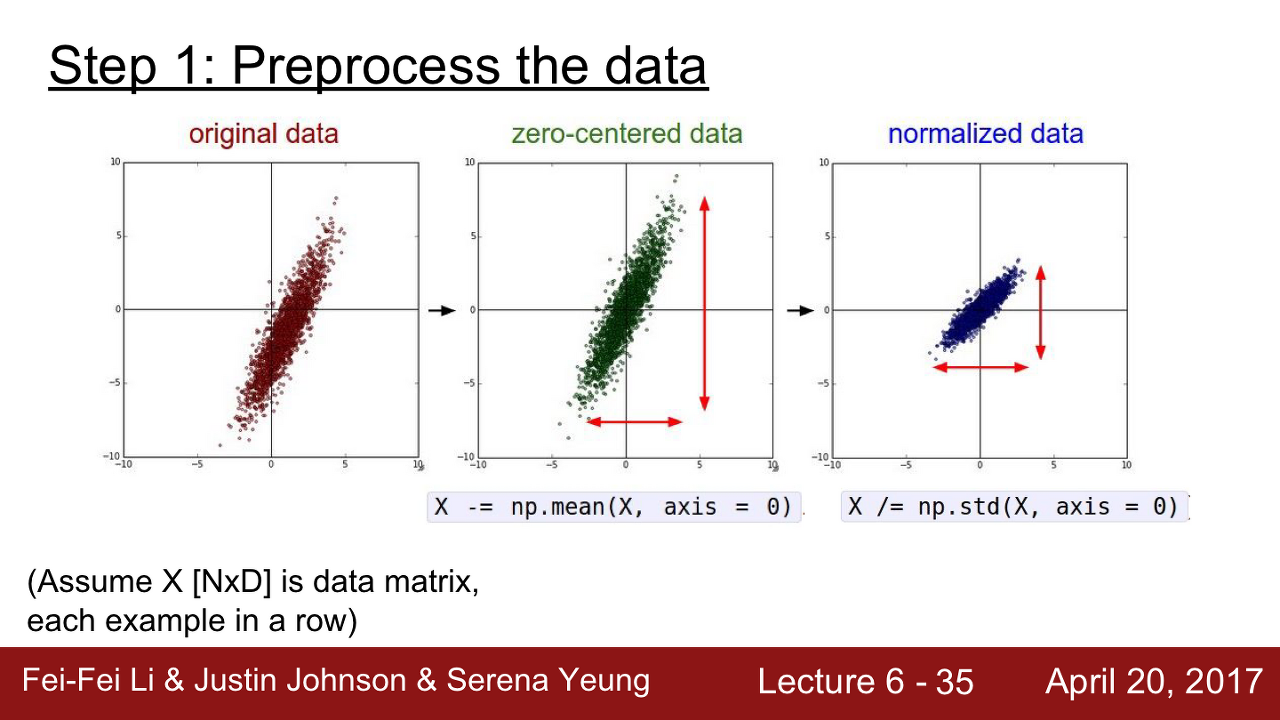
그렇다면 대체 이 작업을 왜 해주는 걸까요?
앞서 우리는 zero-centering에 대해 다뤘습니다. 기억이 나시나요? 슬라이드를 다시 한번 보고 오겠습니다.

입력이 모두 positive일 경우에 대해 다뤘던 적이 있습니다.
입력 값이 모두 positive일 때 발생했던 문제가 기억나시나요?
모든 입력 값이 positive라면 최적의 weight update를 할 수 없는 문제가 발생합니다. 이러한 문제를 해결하기 위한 방법으로 입력값에 zero-mean 값을 빼서 zero-centered되게 만들어줍니다.
normalization을 하는 이유
normalization을 해주는 이유는 모든 차원이 동일한 범위안에 있게 해 줘서 전부 동등한 기여(contribute)를 하기 위함입니다.
실제로는 이미지의 경우 zero-centering정도만 해줍니다. 왜냐하면 이미지는 이미 각 차원 간에 스케일이 어느 정도 맞춰져 있기 때문입니다.
따라서 스케일이 다양한 여러 ML 문제와는 달리 이미지에서는 normalization을 엄청 잘 해줄 필요는 없습니다.
그리고 ML에서는 PCA나 whitening 같은 더 복잡한 전처리 과정이 있었습니다. 이미지에서는 단순히 zero-mean정도만 합니다.
한편 일반적으로는 이미지를 다룰 때 굳이 더 낮은 차원으로 projection하지 않습니다.
CNN에서는 원본 이미지 자체의 spatial 정보를 이용해서 이미지의 spatial structure를 얻을 수 있도록 합니다.
Q. 그렇다면 Training Phase에서 전처리를 해줬으면 Test Phase에서도 똑같은 전처리를 해줘야 하는 건가요?
A. Yes, 네 맞습니다.
요약

이미지를 다룰때는 기본적으로 zero-mean 전처리를 해준다는 것입니다.
평균값은 전체 Training data에서 계산합니다.
보통 입력이미지의 사이즈를 서로 맞춰줍니다. 네트워크에 들어가기 전에 평균값을 빼주게 됩니다.
Test시 이미지에도 Training time에 계산한 평균 값을 빼줍니다.
실제 일부 네트워크는 채널 전체의 평균을 구하지 않고 채널마다 평균을 독립적으로 계산하는 경우도 있습니다.
채널별로 평균을 비슷하게 할 것인지 아니면 채널마다 독립적으로 평균을 계산할 것인지는 학습자가 판단하여 정해주면 됩니다.
AlexNet 이후의 VGGNet 같은 경우가 채널의 독립적인 평균값을 빼주는 식으로 전처리를 합니다.
기타 질문들...
Q1. 채널의 의미
A1. R, G, B 채널을 의미합니다.
Q2. 평균을 어떻게 구하나요?
A2. 모든 학습 데이터를 사용하여 평균을 구할 수 있습니다.
Q3. 미니 배치단위로 학습시켜도 평균은 미니 배치 단위가 아닌 전체로 계산하는 건가요?
A3. Yes, 네 맞습니다.
우리가 구하려는 평균은 트레이닝 데이터의 평균입니다.
Q4. 데이터 전처리로 zero-mean 평균값을 빼주면 Sigmoid Problem을 해결해 줄 수 있나요?
A4. 우리가 수행할 전 처리는 zero-mean 평균입니다. 앞서 sigmoid 에게는 zero-mean이 필요하다고 했습니다.
데이터 전처리가 sigmoid의 zero-mean 문제를 단지 '첫 번째'레이어에서만 해결할 수 있을 것입니다. 레이어가 깊어질수록 문제는 심화될 것입니다. 따라서 이미지 전처리가 Sigmoid 문제를 해결하기에는 적절하지 않습니다.
Summary
이번 시간은 Data Preprocessing에 대해 간단히 배워봤습니다. (간단했던 만큼 Summary도 제공됩니다!)
이것 하나만큼은 꼭 기억해주세요!
zero-mean 전처리를 해줍니다.
데이터가 네트워크의 입력값으로 들어가기 전 트레이닝 데이터의 평균 값을 빼주세요
이상 Steve-Lee였습니다. 긴 글 읽어주셔서 감사합니다. 좋은 하루 보내세요!
'Deep Learning > 모두를 위한 cs231n' 카테고리의 다른 글
| [모두를 위한 cs231n] Lecture 13 - Part 2. VAE(Variational AutoEncoer) (3) | 2020.06.19 |
|---|---|
| [모두를 위한 cs231n] Lecture 6. Batch Normalization에 대해 알아보자 (4) | 2020.05.19 |
| [모두를 위한 cs231n] Lecture 6. Weight Initialization (0) | 2020.05.18 |
| [모두를 위한 cs231n] Lecture 6. Activation Functions에 대해 알아보자 (1) | 2020.05.18 |
| [모두를 위한 cs231n] Lecture 8 - Part3. TensorFlow Framework (0) | 2020.05.12 |




댓글